2023
 PhD Thesis: Exploring the role of (self-)attention in cognitive and computer vision architectureVaishnav, MohitarXiv, cs.AI 2023
PhD Thesis: Exploring the role of (self-)attention in cognitive and computer vision architectureVaishnav, MohitarXiv, cs.AI 2023We investigate the role of attention and memory in complex reasoning tasks. We analyze Transformer-based self-attention as a model and extend it with memory. By studying a synthetic visual reasoning test, we refine the taxonomy of reasoning tasks. Incorporating self-attention with ResNet50, we enhance feature maps using feature-based and spatial attention, achieving efficient solving of challenging visual reasoning tasks. Our findings contribute to understanding the attentional needs of SVRT tasks. Additionally, we propose GAMR, a cognitive architecture combining attention and memory, inspired by active vision theory. GAMR outperforms other architectures in sample efficiency, robustness, and compositionality, and shows zero-shot generalization on new reasoning tasks.
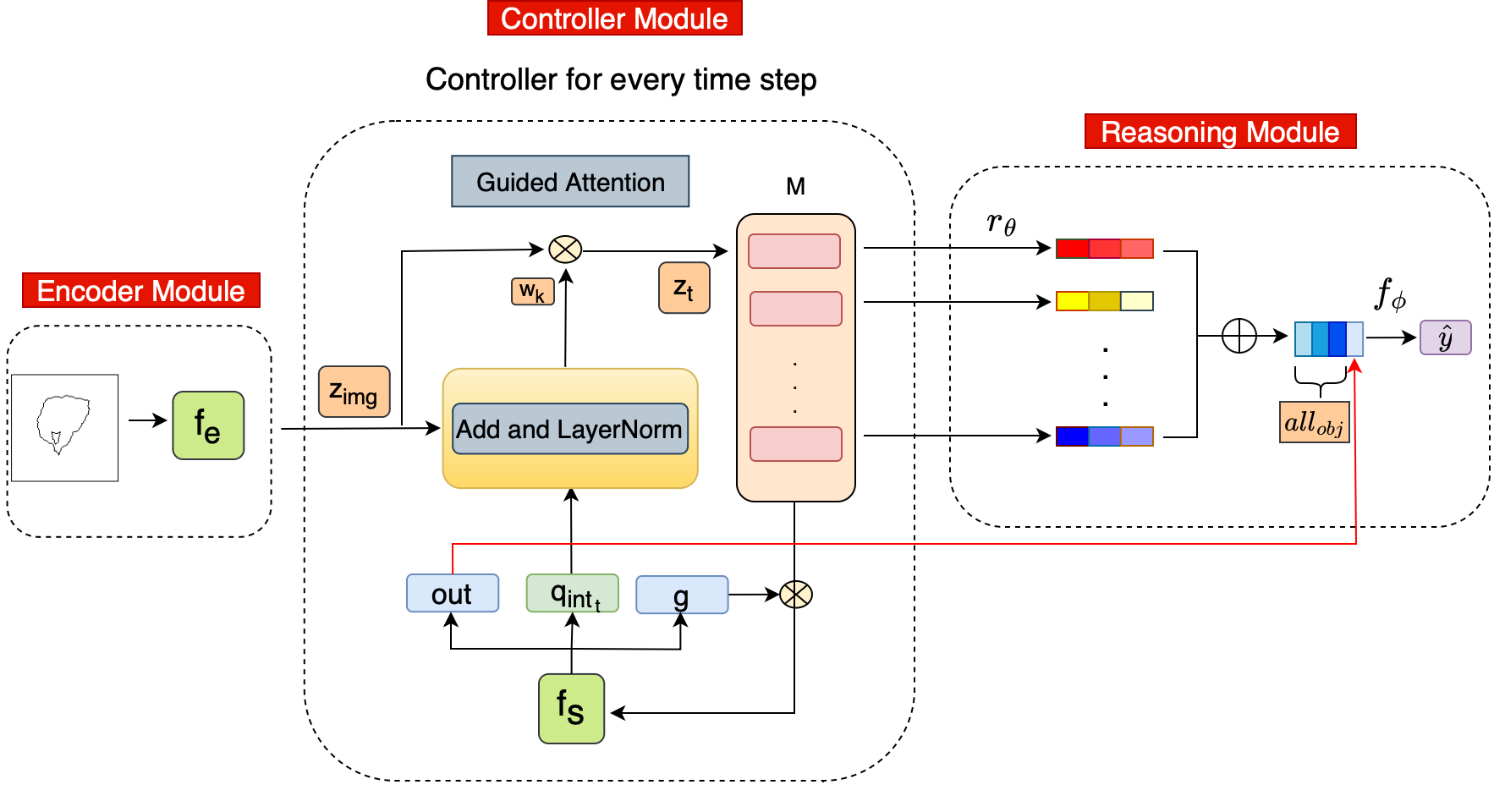 GAMR: Guided Attention Model for (visual) ReasoningVaishnav, Mohit and Serre, ThomasInternational Conference on Learning Representations ICLR 2023
GAMR: Guided Attention Model for (visual) ReasoningVaishnav, Mohit and Serre, ThomasInternational Conference on Learning Representations ICLR 2023Humans continue to outperform modern AI systems in their ability to flexibly parse and understand complex visual scenes. Here, we present a novel module for visual reasoning, the Guided Attention Model for (visual) Reasoning (GAMR), which instantiates an active vision theory – positing that the brain solves complex visual reasoning problems dynamically – via sequences of attention shifts to select and route task-relevant visual information into memory. Experiments on an array of visual reasoning tasks and datasets demonstrate GAMR’s ability to learn visual routines in a robust and sample-efficient manner. In addition, GAMR is shown to be capable of zero-shot generalization on completely novel reasoning tasks. Overall, our work provides computational support for cognitive theories that postulate the need for a critical interplay between attention and memory to dynamically maintain and manipulate task-relevant visual information to solve complex visual reasoning tasks.
2022
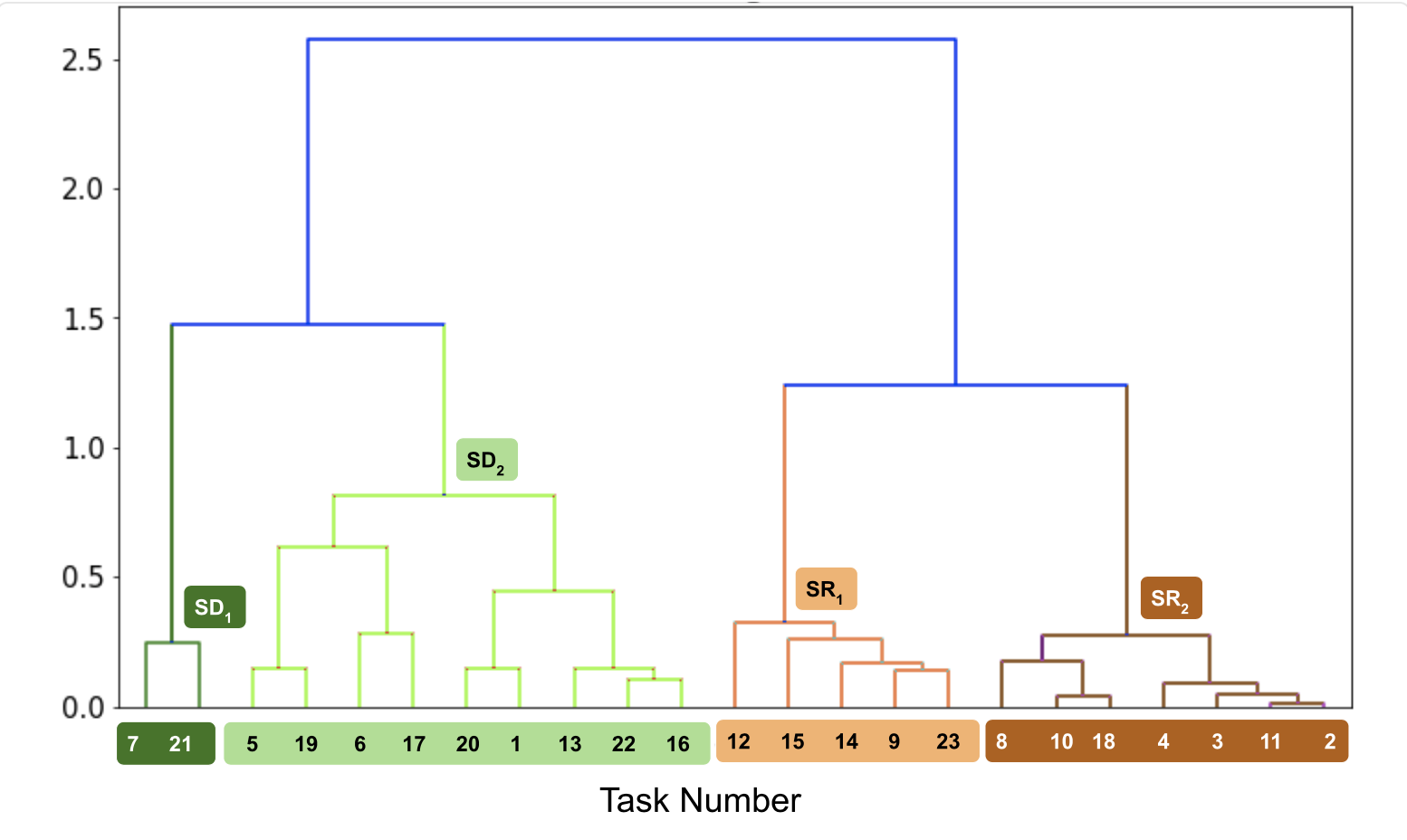 Understanding the Computational Demands Underlying Visual ReasoningVaishnav, Mohit Cadene, Remi, Alamia, Andrea, Linsley, Drew, VanRullen, Rufin, and Serre, ThomasSpecial Collection CogNet of Neural Computation 2022
Understanding the Computational Demands Underlying Visual ReasoningVaishnav, Mohit Cadene, Remi, Alamia, Andrea, Linsley, Drew, VanRullen, Rufin, and Serre, ThomasSpecial Collection CogNet of Neural Computation 2022Visual understanding requires comprehending complex visual relations between objects within a scene. Here, we seek to characterize the computational demands for abstract visual reasoning. We do this by systematically assessing the ability of modern deep convolutional neural networks (CNNs) to learn to solve the synthetic visual reasoning test (SVRT) challenge, a collection of 23 visual reasoning problems. Our analysis reveals a novel taxonomy of visual reasoning tasks, which can be primarily explained by both the type of relations (same-different versus spatial-relation judgments) and the number of relations used to compose the underlying rules. Prior cognitive neuroscience work suggests that attention plays a key role in humans’ visual reasoning ability. To test this hypothesis, we extended the CNNs with spatial and feature-based attention mechanisms. In a second series of experiments, we evaluated the ability of these attention networks to learn to solve the SVRT challenge and found the resulting architectures to be much more efficient at solving the hardest of these visual reasoning tasks. Most important, the corresponding improvements on individual tasks partially explained our novel taxonomy. Overall, this work provides a granular computational account of visual reasoning and yields testable neuroscience predictions regarding the differential need for feature-based versus spatial attention depending on the type of visual reasoning problem.
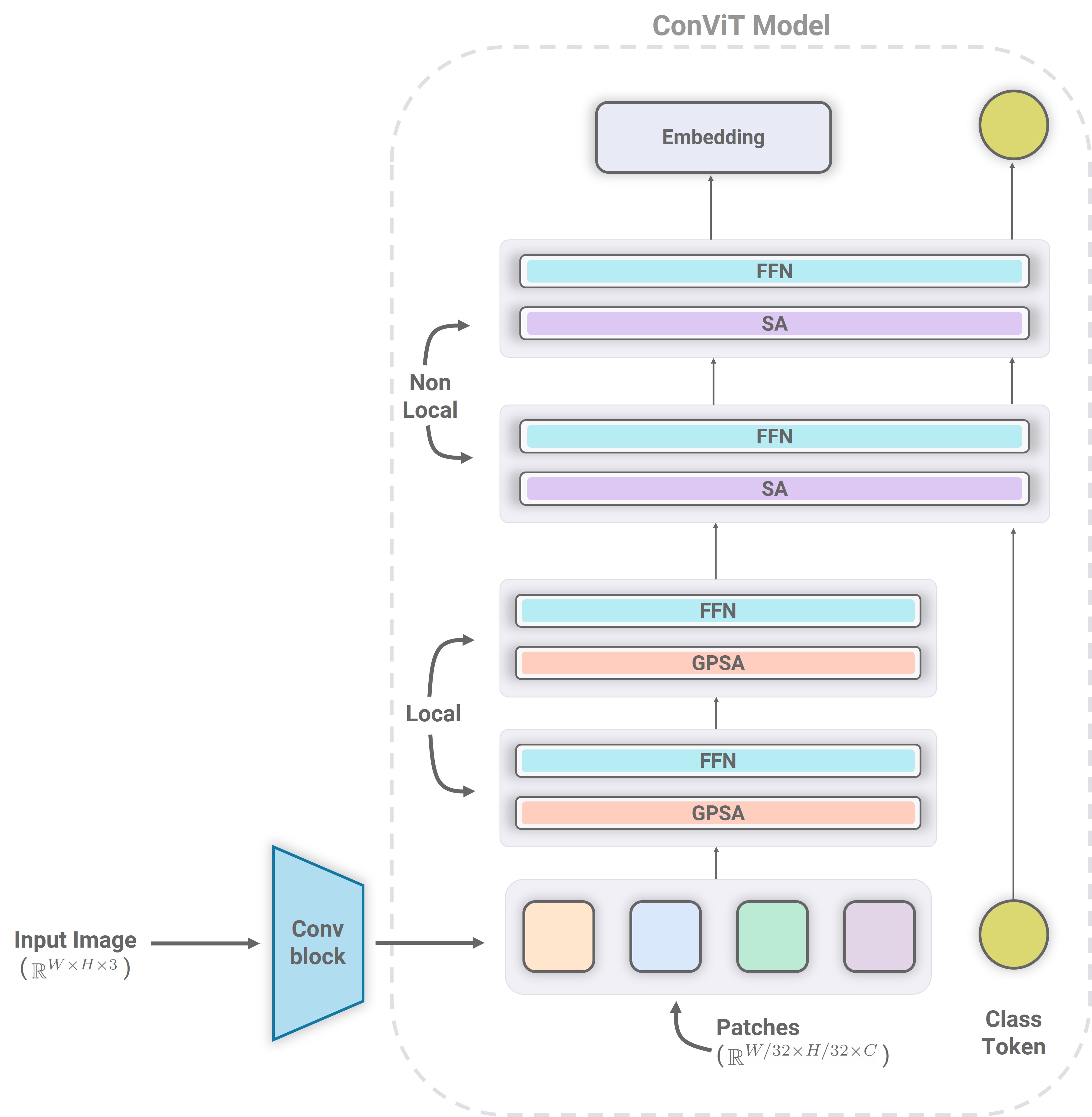 Conviformers: Convolutionally guided Vision TransformerVaishnav, Mohit Fel, Thomas, Rodrıguez, Ivan Felipe, and Serre, ThomasarXiv preprint arXiv:2208.08900 2022
Conviformers: Convolutionally guided Vision TransformerVaishnav, Mohit Fel, Thomas, Rodrıguez, Ivan Felipe, and Serre, ThomasarXiv preprint arXiv:2208.08900 2022Vision transformers are nowadays the de-facto preference for image classification tasks. There are two broad categories of classification tasks, fine-grained and coarse-grained. In fine-grained classification, the necessity is to discover subtle differences due to the high level of similarity between sub-classes. Such distinctions are often lost as we downscale the image to save the memory and computational cost associated with vision transformers (ViT). In this work, we present an in-depth analysis and describe the critical components for developing a system for the fine-grained categorization of plants from herbarium sheets. Our extensive experimental analysis indicated the need for a better augmentation technique and the ability of modern-day neural networks to handle higher dimensional images. We also introduce a convolutional transformer architecture called Conviformer which, unlike the popular Vision Transformer (ConViT), can handle higher resolution images without exploding memory and computational cost. We also introduce a novel, improved pre-processing technique called PreSizer to resize images better while preserving their original aspect ratios, which proved essential for classifying natural plants. With our simple yet effective approach, we achieved SoTA on Herbarium 202x and iNaturalist 2019 dataset.
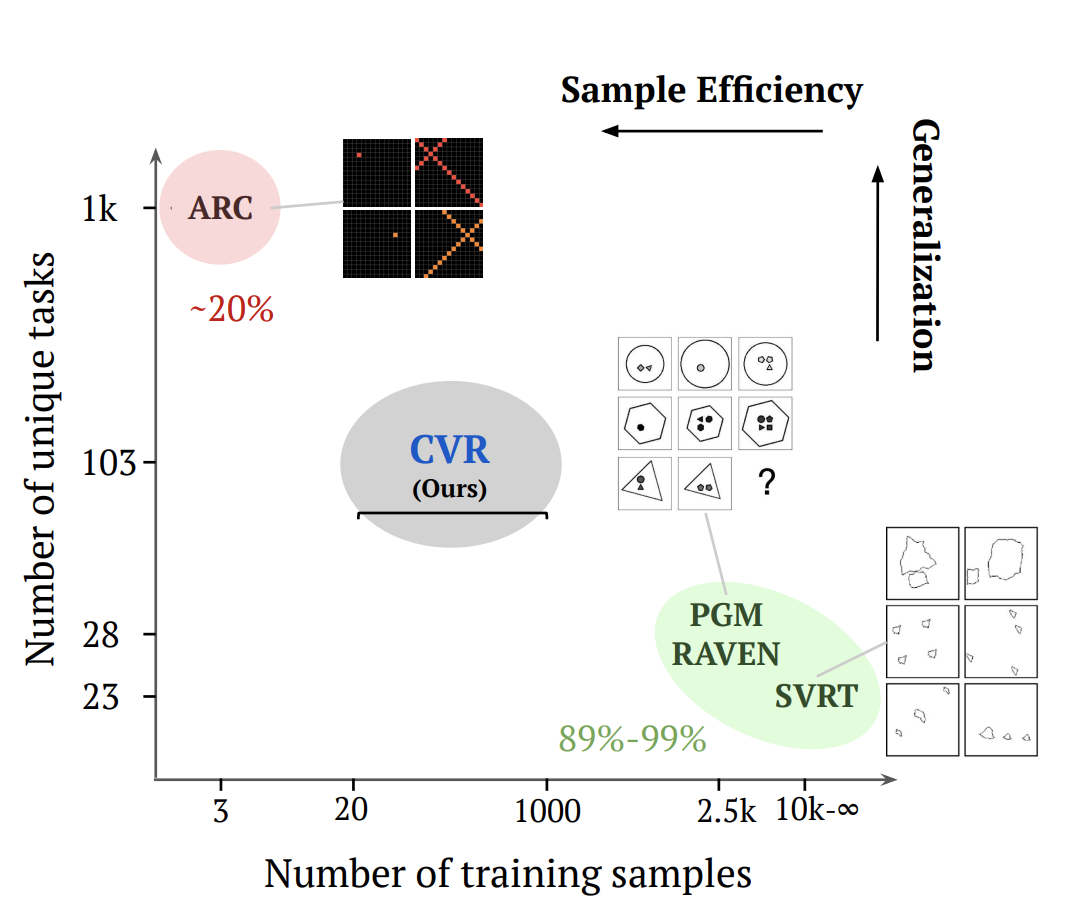 A Benchmark for Compositional Visual ReasoningZerroug, Aimen Vaishnav, Mohit, Colin, Julien, Musslick, Sebastian, and Serre, ThomasIn Proceedings of the Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks 2022
A Benchmark for Compositional Visual ReasoningZerroug, Aimen Vaishnav, Mohit, Colin, Julien, Musslick, Sebastian, and Serre, ThomasIn Proceedings of the Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks 2022A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans’ remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality – such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
2014
 Residue Coding Technique for Video CompressionVaishnav, Mohit Tewani, Binny, and Tiwari, Anil KumarIn Data Compression Conference, DCC, Snowbird, UT, USA, 26-28 March 2014
Residue Coding Technique for Video CompressionVaishnav, Mohit Tewani, Binny, and Tiwari, Anil KumarIn Data Compression Conference, DCC, Snowbird, UT, USA, 26-28 March 2014All the methods available in literature for lossless coding comprises of two steps, one is the prediction scheme that results into prediction error and the second one consists of entropy coding of prediction error samples. In this work we introduce a scheme which adds a step prior to entropy coding technique due to which, the achieved gain in terms of compression is high. The additional step works on the predicted error frames obtained after applying any prediction scheme. The error frames so obtained are remapped into another domain of 8 bits per error sample. While remapping, two files are generated which needs to be compressed, One is the remapped error file itself while the second file consists of overhead information needed to get back the original error samples. The second file consists of binary numbers. The remapped file is compressed by CALIC encoder while the other is kept as it is, causing an addition of one bit per pixel overhead to the compressed file. Results show that instead of going in a traditional manner if we follow the proposed path, there will be a gain of about 0.21 bpp on an average. Additionally the comparison has also been made against other prominent codecs like JPEG and CALIC.
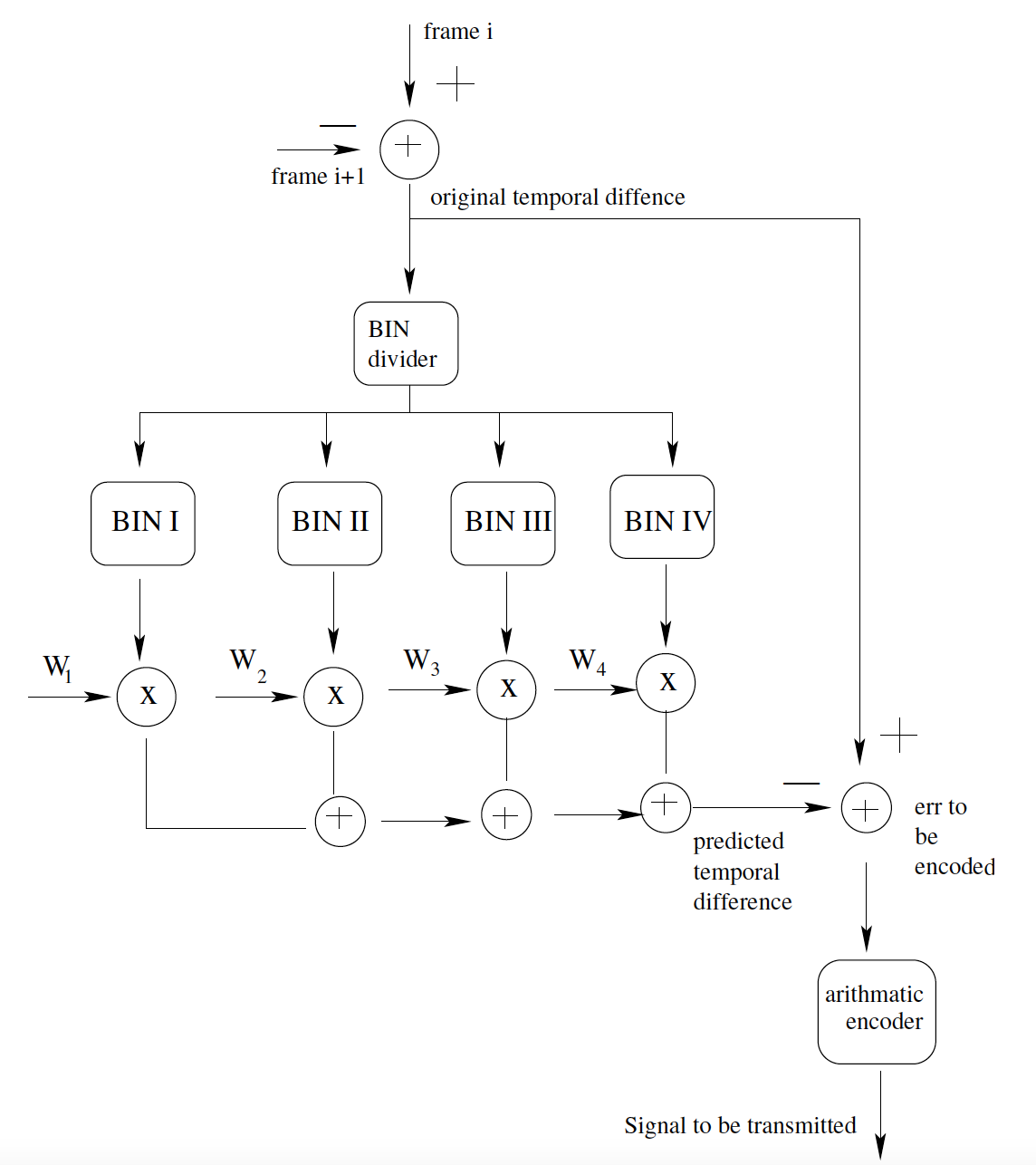 Bin Classification Using Temporal Gradient Estimation for Lossless Video CodingVaishnav, Mohit and Tiwari, Anil KumarIn Data Compression Conference, DCC, Snowbird, UT, USA, 26-28 March 2014
Bin Classification Using Temporal Gradient Estimation for Lossless Video CodingVaishnav, Mohit and Tiwari, Anil KumarIn Data Compression Conference, DCC, Snowbird, UT, USA, 26-28 March 2014In this paper, a novel method for lossless compression of video is proposed. Almost all the prediction based methods reported in literature are of two pass. In the first pass, motion compensated frame is obtained and in the second, some sophisticated method is used to predict the pixels of the current frame. The proposed method is an efficient replacement for the first method that predicts current pixel using an estimate of deviation from the pixel at same temporal location in the previous frame. In this scheme, causal pixels are divided into bins based on the distance between the current and causal pixels. The novelty of the work is in finding out the fixed coefficients of the bins for a particular type of video sequence. The overall performance of the proposed method is same with much lower computational complexity.
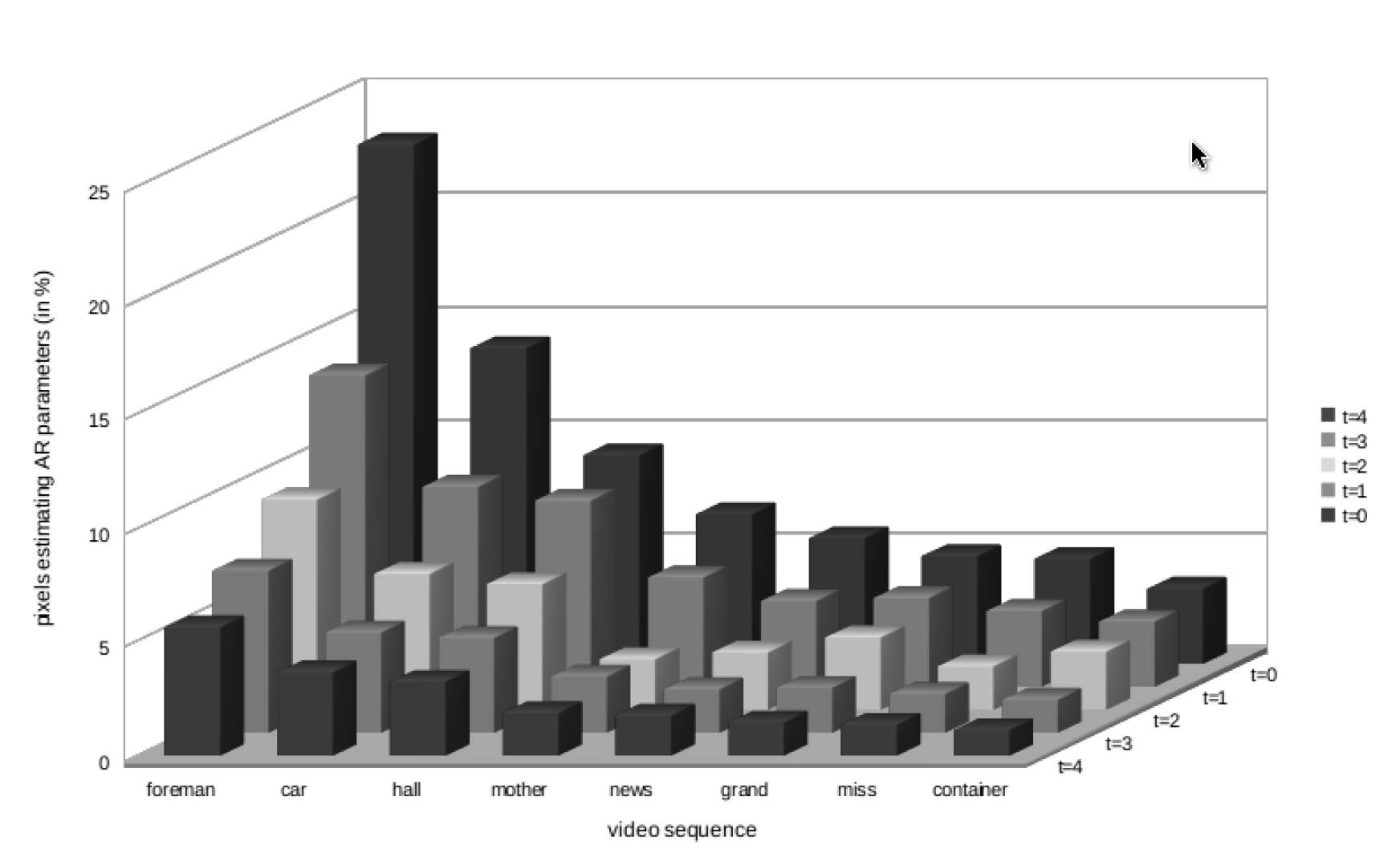 Temporal Stationarity Based Prediction Method For Lossless Video CodingVaishnav, Mohit Chobey, Dinesh Kumar, and Tiwari, Anil KumarIn Proceedings of Indian Conference on Computer Vision, Graphics and Image Processing, ICVGIP, Bangalore, India, December 14-18 2014
Temporal Stationarity Based Prediction Method For Lossless Video CodingVaishnav, Mohit Chobey, Dinesh Kumar, and Tiwari, Anil KumarIn Proceedings of Indian Conference on Computer Vision, Graphics and Image Processing, ICVGIP, Bangalore, India, December 14-18 2014
2013
- An Optimal Switched Adaptive Prediction Method for Lossless Video CodingChobey, Dinesh Kumar Vaishnav, Mohit, and Tiwari, Anil KumarIn Data Compression Conference, DCC, Snowbird, UT, USA, March 20-22 2013
In this work, we propose a method of lossless video coding which not has only the decoder simple but encoder is also simple, unlike other reported methods which has computationally complex encoder. The computation is mainly due to not using motion compensation method, which is computationally complex process. The coefficient of the predictors are obtained based on an averaging process and then the thus obtained set of switched predictors is used for prediction. The parameters have been obtained after undergoing a statistical process of averaging so that proper relationship can be established between the predicted pixel and their context.
2011
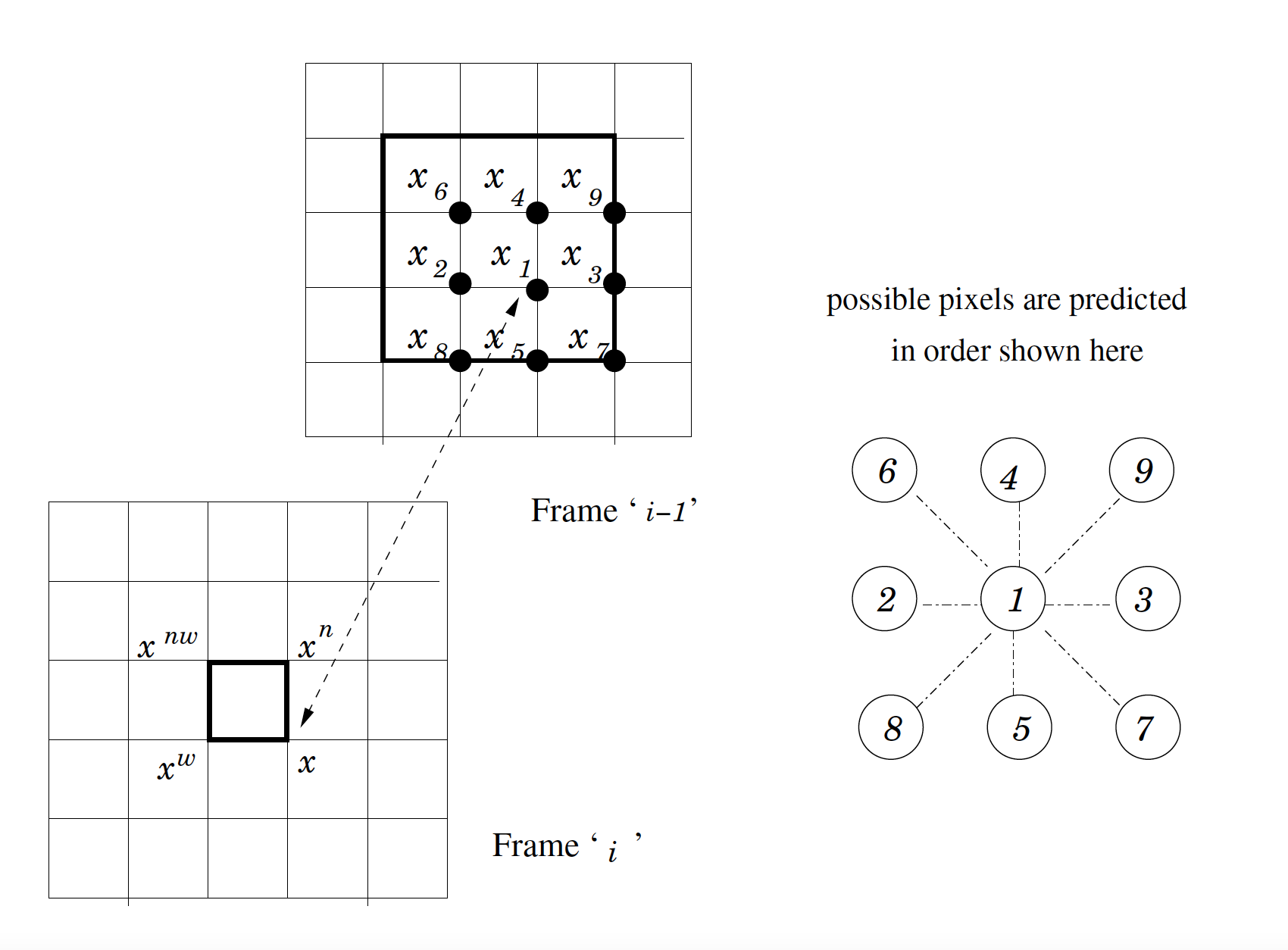 A Novel Computationally Efficient Motion Compensation Method Based on Pixel by Pixel PredictionVaishnav, Mohit Sharma, Ashwani, and Tiwari, Anil KumarIn Data Compression Conference (DCC), 29-31 March, Snowbird, UT, USA 2011
A Novel Computationally Efficient Motion Compensation Method Based on Pixel by Pixel PredictionVaishnav, Mohit Sharma, Ashwani, and Tiwari, Anil KumarIn Data Compression Conference (DCC), 29-31 March, Snowbird, UT, USA 2011This paper presents a novel loss less compression method for video. In this work, we propose a novel method for finding motion compensated frame. This is computationally much efficient than other method reported in literature. After finding the motion compensated frame, we propose a new method for efficiently applying LS based predictor on the frames. The predictor structure uses pixels in the current frame and also in the motion compensated frame. Overall performance of the proposed method is significantly better than many competitive methods at significantly reduced computational complexity.